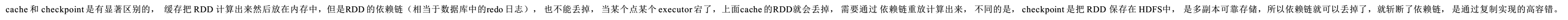Spark 第二天之RDD
1. RDD概念
1.1 为什么要学习RDD
RDD是Spark的基石,是实现Spark数据处理的核心抽象。那么RDD为什么会产生呢?
Hadoop的MapReduce是一种基于数据集的工作模式,面向数据,这种工作模式一般是从存储上加载数据集,然后操作数据集,最后写入物理存储设备。数据更多面临的是一次性处理。
MR的这种方式对数据领域两种常见的操作不是很高效。第一种是迭代式的算法。比如机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。
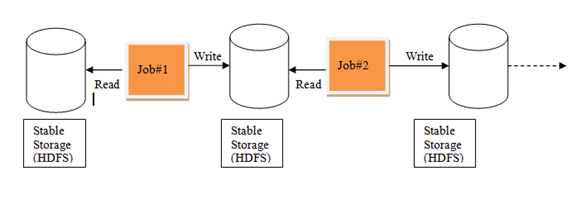
MR中的迭代:
![image_1cmftqjpr1iv51ej5cvc2lg1hf89.png-27.9kB][1]
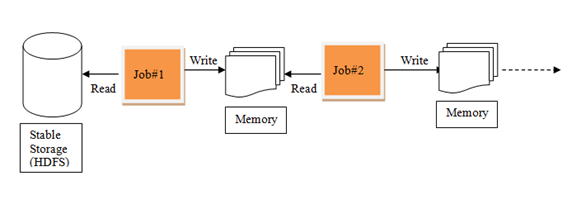
Spark中的迭代:
![image_1cmftrru117341tc9q2h10m9h8g16.png-21.7kB][2]
我们需要一个效率非常快,且能够支持迭代计算和有效数据共享的模型,Spark应运而生。RDD是基于工作集的工作模式,更多的是面向工作流。但是无论是MR还是RDD都应该具有类似位置感知、容错和负载均衡等特性。
1.2 什么是RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象, 甚至可以包含用户自定义的对象。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD支持两种操作:转化操作和行动操作。RDD 的转化操作是返回一个新的 RDD的操作,比如 map()和 filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如 count() 和 first()。
Spark采用惰性计算模式,RDD只有第一次在一个行动操作中用到时,才会真正计算。Spark可以优化整个计算过程。默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来。
1.3 RDD的属性
![image_1cmfus9721d7iom1pllav1b8k3g.png-38.1kB][3]
一组分片(Partition)
即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。一个计算每个分区的函数。
Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。RDD之间的依赖关系。
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。一个Partitioner
即RDD的分区函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。一个列表,存储存取每个Partition的优先位置(preferred location)。
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
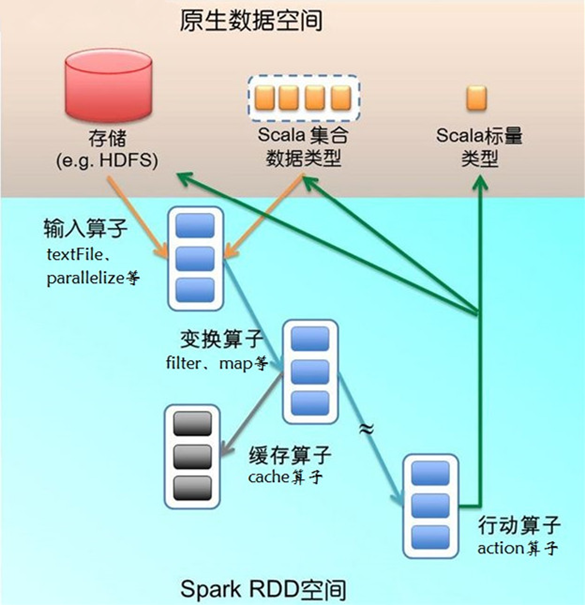
RDD是一个应用层面的逻辑概念。一个RDD多个分片。RDD就是一个元数据记录集,记录了RDD内存所有的关系数据。
![image_1cmfuvvr5c8k1il2qor1pe6gnp3t.png-360.8kB][4]
1.4 RDD的弹性
- 自动进行内存和磁盘数据存储的切换
Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换 - 基于血统关系高效容错机制
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据。 - 任务失败会自动重试
RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次。 - 数据分区的高度弹性
可以根据业务的特征,动态调整数据分区的个数,提升整体的应用执行效率。
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持丰富的转换操作(如map, join, filter, groupBy等),通过这种转换操作,新的RDD则包含了如何从其他RDDs衍生所必需的信息,所以说RDDs之间是有依赖关系的。基于RDDs之间的依赖,RDDs会形成一个有向无环图DAG,该DAG描述了整个流式计算的流程,实际执行的时候,RDD是通过血缘关系(Lineage)一气呵成的,即使出现数据分区丢失,也可以通过血缘关系重建分区,总结起来,基于RDD的流式计算任务可描述为:从稳定的物理存储(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的DAG,然后写回稳定存储。另外RDD还可以将数据集缓存到内存中,使得在多个操作之间可以重用数据集,基于这个特点可以很方便地构建迭代型应用(图计算、机器学习等)或者交互式数据分析应用。可以说Spark最初也就是实现RDD的一个分布式系统,后面通过不断发展壮大成为现在较为完善的大数据生态系统,简单来讲,Spark-RDD的关系类似于Hadoop-MapReduce关系。
1.5 RDD的特点
- 分区
- RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
- 只读
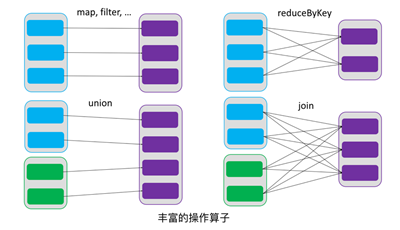
- 但是RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了。如下图所示:
![image_1cmfvpaiv10rcqhlh7e1jrr8hu4q.png-34.7kB][5]
RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。下图是RDD所支持的操作算子列表。
![image_1cmfvq4lqq5p1mqo1coc1efdac657.png-79.7kB][6]
- 依赖
- RDD之间的转换操作需要一个关系信息,这些信息或者说这种血缘关系就成为一个依赖。依赖分为窄依赖和宽依赖。窄依赖:RDD的分区是一一对应的。宽依赖:下游的RDD的每个分区都与上游RDD的每个分区都有关系,说白了就是多对多的关系。
- 缓存
- 如果程序中需要多次使用一个RDD,可以将缓存的内容存储起来。
- checkpoint
- checkpoint可以将数据持久化到存储中。可以切断血缘关系,后续的可以直接从checkpoint中拿到
RDD的信息包含以下内容
- 分区数,分区方式
- 上游RDD衍生而来的依赖关系
- 计算每个分区的数据
- 如果这个数据被缓存了,那么就直接从内存读取数据 - 如果这个数据被checkpoint了,那么就从checkpoint恢复数据 - 根据依赖计算数据
2. RDD的方法
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
2.1 RDD的创建
在Spark中创建RDD的创建方式大概可以分为三种:
从集合中创建RDD
1
2
3
4
5
6
7# 创建RDD,其实底层还是parallelize
sc.makeRDD(1 to 10)
sc.parallelize(1 to 10)
res2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:25
res2.collect
res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
- 从外部存储创建RDD
- 从其他RDD创建。
2.2 RDD的类型
- 数值型RDD(单一值)
RDD[Int]、 RDD[(Int,Int)] 、 RDD[(Int,(Int,Int))] RDD.scala - 键值对RDD
RDD[Int,Int] RDD[(Int,(Int,Int))] PairRDDFunctions.scala [所有键值对RDD都可以使用数据型RDD的操作]
2.3 RDD的转换
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
常用的Transformation
:
- map(func)
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成1
2
3
4
5
6
7
8sc.makeRDD(1 to 10)
res4: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at makeRDD at <console>:25
res4.map(_ * 3)
res5: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map at <console>:27
res5.collect
res6: Array[Int] = Array(3, 6, 9, 12, 15, 18, 21, 24, 27, 30)
filter(func)
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成,,过滤数据1
2
3
4
5sc.makeRDD(1 to 20)
res7: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at makeRDD at <console>:25
res7.filter(_ % 2 == 0).collect
res8: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)flatMap(func)
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素),一对多1
2
3
4
5
6
7
8sc.makeRDD(1 to 10)
res9: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at makeRDD at <console>:25
res9.flatMap(1 to _)
res10: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[7] at flatMap at <console>:27
res10.collect
res11: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)mapPartitions(func)
类似于map,但独立地在RDD的每一个分区上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。对于一个分区中的所有数据执行一个函数,性能比map要高1
2
3
4
5
6
7
8
9
10
11var rdd = sc.makeRDD(List((1,1001),(2,1002),(3,1003),(4,1004),(5,1005)))
def pf(is:Iterator[(Int,Int)]):Iterator[String]={
var list = List[String]()
while(is.hasNext){
val tuble = is.next()
list = (tuble._1 + "hehe"+tuble._2)::list
}
list.iterator
}
val res = rdd.mapPartitions(pf)
res.collectmapPartitionsWithIndex(func)
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U]- sample(withReplacement, fraction, seed)
以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。例子从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1 2 3的其中一个起始值)。主要用于抽样1
2
3
4
5
6
7
8val rdd = sc.makeRDD(1 to 100)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at makeRDD at <console>:24
rdd.sample(true,0.1,10)
res22: org.apache.spark.rdd.RDD[Int] = PartitionwiseSampledRDD[17] at sample at <console>:27
res22.collect
res23: Array[Int] = Array(2, 4, 20, 20, 53, 60, 67, 82, 92, 93)
- sample(withReplacement, fraction, seed)
takeSample
和Sample的区别是:takeSample返回的是最终的结果集合。1
2rdd.takeSample(true,7,4)
res55: Array[Int] = Array(36, 45, 40, 34, 100, 57, 67)union(otherDataset)
对源RDD和参数RDD求并集后返回一个新的RDD1
2sc.makeRDD(1 to 10).union(sc.makeRDD(20 to 25)).collect
res57: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 21, 22, 23, 24, 25)intersection(otherDataset)
对源RDD和参数RDD求交集后返回一个新的RDD。求交集1
2
3
4
5sc.makeRDD(1 to 10).intersection(sc.makeRDD(20 to 25)).collect
res58: Array[Int] = Array()
sc.makeRDD(1 to 10).intersection(sc.makeRDD(5 to 20)).collect
res59: Array[Int] = Array(6, 9, 7, 10, 8, 5)
distinct([numTasks]))
对源RDD进行去重后返回一个新的RDD. 默认情况下,只有6个并行任务来操作,但是可以传入一个可选的numTasks参数改变它。1
2
3
4
5sc.makeRDD(1 to 10).union(sc.makeRDD(5 to 15)).collect
res60: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15)
sc.makeRDD(1 to 10).union(sc.makeRDD(5 to 15)).distinct.collect
res61: Array[Int] = Array(6, 12, 13, 1, 7, 14, 8, 2, 15, 3, 9, 4, 10, 11, 5)- partitionBy
对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD1
2
3
4
5
6
7
8
9import org.apache.spark.HashPartitioner
import org.apache.spark.HashPartitioner
rdd.map(v => (v,v)).partitionBy(new HashPartitioner(6))
res64: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[85] at partitionBy at <console>:28
res64.partitions.size
- partitionBy
reduceByKey(func, [numTasks])
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置groupByKey
groupByKey也是对每个key进行操作,但只生成一个sequence。将key相同的value聚集在一起。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31val line = "acdfakdfakdfadsajdvakldjfahdsfajdsfhasfa"
line: String = acdfakdfakdfadsajdvakldjfahdsfajdsfhasfa
val rdd = sc.makeRDD(line)
rdd: org.apache.spark.rdd.RDD[Char] = ParallelCollectionRDD[86] at makeRDD at <console>:27
rdd.collect
res66: Array[Char] = Array(a, c, d, f, a, k, d, f, a, k, d, f, a, d, s, a, j, d, v, a, k, l, d, j, f, a, h, d, s, f, a, j, d, s, f, h, a, s, f, a)
rdd.map(w=>(w,1)).groupByKey().collect
res67: Array[(Char, Iterable[Int])] = Array((f,CompactBuffer(1, 1, 1, 1, 1, 1, 1)), (l,CompactBuffer(1)), (c,CompactBuffer(1)), (d,CompactBuffer(1, 1, 1, 1, 1, 1, 1, 1)), (s,CompactBuffer(1, 1, 1, 1)), (a,CompactBuffer(1, 1, 1, 1, 1, 1, 1, 1, 1, 1)), (j,CompactBuffer(1, 1, 1)), (v,CompactBuffer(1)), (k,CompactBuffer(1, 1, 1)), (h,CompactBuffer(1, 1)))
rdd.map(w=>(w,1)).reduceByKey(_+_).collect
res68: Array[(Char, Int)] = Array((f,7), (l,1), (c,1), (d,8), (s,4), (a,10), (j,3), (v,1), (k,3), (h,2))
rdd.map(w=>(w,1)).reduceByKey(_+"->"+_).collect
<console>:30: error: type mismatch;
found : String
required: Int
rdd.map(w=>(w,1)).reduceByKey(_+"->"+_).collect
^
rdd.map(w=>(w,1)).reduceByKey((v1,v2)=>v1+"->"+v2).collect
<console>:30: error: type mismatch;
found : String
required: Int
rdd.map(w=>(w,1)).reduceByKey((v1,v2)=>v1+"->"+v2).collect
^
rdd.map(w=>(w,1)).reduceByKey((v1,v2)=>v1+v2+100).collect
res71: Array[(Char, Int)] = Array((f,607), (l,1), (c,1), (d,708), (s,304), (a,910), (j,203), (v,1), (k,203), (h,102))combineByKey[C]
对相同K,把V合并成一个集合.1
2
3
4
5
6
7
8
9
10
11
12createCombiner: V => C, 遍历分区中所有的元素,使用这个函数可以来创建一个累加器的初始值v=>(v,1)
mergeValue: (C, V) => C, 可以将当前这个分区中所遇到的值和当前的值累加(c:(Int,Int),v)=>(c._1+v,c._2+1)
mergeCombiners: (C, C) => C,将多个分区的值累加后在累加(c1:(Int,Int),c2:(Int,Int))=>(c1._1+c2._1,c1._2+c2._2)
求学生成绩的平均值
val rdd1 = sc.makeRDD(List(("a",90),("a",60),("a",70),("b",96),("b",80),("b",70),("c",60),("c",80),("c",80)))
rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[93] at makeRDD at <console>:25
rdd1.combineByKey(v=>(v,1),(c:(Int,Int),v)=>(c._1+v,c._2+1),(c1:(Int,Int),c2:(Int,Int))=>(c1._1+c2._1,c1._2+c2._2))
res72: org.apache.spark.rdd.RDD[(String, (Int, Int))] = ShuffledRDD[94] at combineByKey at <console>:28
res72.collect
res73: Array[(String, (Int, Int))] = Array((c,(220,3)), (a,(220,3)), (b,(246,3)))aggregateByKey(zeroValue)(sqpOp,combOp)
在kv对的RDD中,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。1
2
3
4
5
6# 举例:对相同的key,求出value的最大值。假设所有value都是大于0的
val rdd2 = sc.makeRDD(List((1,2),(1,4),(1,3),(2,5),(2,4),(3,5),(3,3),(3,6)))
rdd2: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[95] at makeRDD at <console>:25
rdd2.aggregateByKey(0)(math.max(_,_),_+_).collect
res77: Array[(Int, Int)] = Array((3,6), (1,7), (2,5))foldByKey(zeroValue)((V,V)=>V)
aggregateByKey的简化操作,seqop和combop相同
sortByKey([ascending], [numTasks])
在一个(K,V)的RDD上调用,返回一个按照key进行排序的(K,V)的RDD。如果Key目前不支持排序,需要with Ordering接口,实现compare方法,告诉spark key的大小判定。sortBy(func,[ascending], [numTasks])
与sortByKey类似,但是更灵活,可以用func先对数据进行处理,按照处理后的数据比较结果排序。1
2
3
4
5
6
7
8val rdd = sc.makeRDD(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[98] at makeRDD at <console>:25
rdd.sortBy(_ % 3).collect
res78: Array[Int] = Array(6, 9, 3, 4, 7, 10, 1, 2, 5, 8)
rdd.sortBy(_ % 3,false).collect
res79: Array[Int] = Array(2, 8, 5, 4, 1, 7, 10, 6, 3, 9)join(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD1
2
3
4
5
6
7
8val rdd = sc.makeRDD(List((1,"aa"),(2,"bb"),(3,"cc")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[111] at makeRDD at <console>:25
val rdd1 = sc.makeRDD(List((1,"11"),(2,"22"),(3,"33"),(4,"44")))
rdd1: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[112] at makeRDD at <console>:25
rdd.join(rdd1).collect
res81: Array[(Int, (String, String))] = Array((3,(cc,33)), (1,(aa,11)), (2,(bb,22)))cogroup(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable ))类型的RDD
cartesian(otherDataset)
笛卡尔积subtract
计算差的一种函数去除两个RDD中相同的元素,不同的RDD将保留下来 。差集1
2
3
4
5
6
7
8
9
10val rdd2 = sc.makeRDD(5 to 15)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:24
rdd1.substract(rdd2).collect
<console>:29: error: value substract is not a member of org.apache.spark.rdd.RDD[Int]
rdd1.substract(rdd2).collect
^
rdd1.subtract(rdd2).collect
res1: Array[Int] = Array(3, 1, 4, 2)pipe(command, [envVars])
对于每个分区,都执行一个perl或者shell脚本,返回输出的RDD1
2
3
4
5
6
7
8
9
10
11val rdd = sc.makeRDD(List("wangguo","yangxiu","xiaozhou","kangkang"),3)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[9] at makeRDD at <console>:24
rdd.pipe("/opt/test/spark/pipe.sh").collect
res4: Array[String] = Array(wangcen, wangguohehe, wangcen, yangxiuhehe, wangcen, xiaozhouhehe, kangkanghehe)
val rdd = sc.makeRDD(List("wangguo","yangxiu","xiaozhou","kangkang"),4)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[11] at makeRDD at <console>:24
rdd.pipe("/opt/test/spark/pipe.sh").collect
res5: Array[String] = Array(wangcen, wangguohehe, wangcen, yangxiuhehe, wangcen, xiaozhouhehe, wangcen, kangkanghehe)coalesce(numPartitions)
缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。repartition(numPartitions)
根据分区数,从新通过网络随机洗牌所有数据。repartitionAndSortWithinPartitions(partitioner)
repartitionAndSortWithinPartitions函数是repartition函数的变种,与repartition函数不同的是,repartitionAndSortWithinPartitions在给定的partitioner内部进行排序,性能比repartition要高。glom
将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]1
2
3
4
5
6
7
8
9
10
11val rdd = sc.makeRDD(1 to 20,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[13] at makeRDD at <console>:24
rdd.glom.collect
res6: Array[Array[Int]] = Array(Array(1, 2, 3, 4), Array(5, 6, 7, 8), Array(9, 10, 11, 12), Array(13, 14, 15, 16), Array(17, 18, 19, 20))
val rdd = sc.makeRDD("gsdjghsdlkgjldfhsdfgasjdsg",5)
rdd: org.apache.spark.rdd.RDD[Char] = ParallelCollectionRDD[15] at makeRDD at <console>:24
rdd.glom.collect
res7: Array[Array[Char]] = Array(Array(g, s, d, j, g), Array(h, s, d, l, k), Array(g, j, l, d, f), Array(h, s, d, f, g), Array(a, s, j, d, s, g))mapValues
针对于(K,V)形式的类型只对V进行操作1
2
3
4
5
6
7
8scala> val rdd = sc.makeRDD(List((1,10001),(2,10002),(1,20001),(3,10003),(2,20002),(4,100004),(5,10005),(3,20003)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[17] at makeRDD at <console>:24
scala> rdd.mapValues(a => a+1).collect
res10: Array[(Int, Int)] = Array((1,10002), (2,10003), (1,20002), (3,10004), (2,20003), (4,100005), (5,10006), (3,20004))
scala> rdd.mapValues(_+1).collect
res11: Array[(Int, Int)] = Array((1,10002), (2,10003), (1,20002), (3,10004), (2,20003), (4,100005), (5,10006), (3,20004))
- 常用的Action算子
- 如果最后不是返回RDD,那么就是行动操作
reduce(f: (T, T) => T): T
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的.1
2
3
4
5
6
7
8val rdd = sc.makeRDD(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[20] at makeRDD at <console>:24
rdd.reduce(_+_)
res12: Int = 55
rdd.reduce((v1,v2)=>v1+v2)
res13: Int = 55collect()
在驱动程序中将数据集的所有元素作为数组返回count()
返回数据集中的元素数first()
返回数据集的第一个元素(类似于take(1))。take(n)
返回一个由数据集的前n个元素组成的数组takeSample(withReplacement,num, [seed])
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子takeOrdered(n)
返回前几个的排序。先排序后拿走saveAsTextFile(path)
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本saveAsSequenceFile(path)
将数据集中的元素以Hadoop sequencefile 的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。saveAsObjectFile(path)
用于将RDD中的元素序列化成对象,存储到文件中。countByKey()
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。foreach(func)
在数据集的每一个元素上,运行函数func进行更新。1
2
3
4
5
6
7
8
9
10
11val rdd = sc.makeRDD(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[25] at makeRDD at <console>:24
var sum = sc.accumulator(0)
warning: there were two deprecation warnings; re-run with -deprecation for details
sum: org.apache.spark.Accumulator[Int] = 0
rdd.foreach(sum+=_)
sum.value
res27: Int = 55
- 数值型RDD的统计操作
- Spark 对包含数值数据的 RDD 提供了一些描述性的统计操作。 Spark 的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些 统计数据都会在调用 stats() 时通过一次遍历数据计算出来,并以 StatsCounter 对象返回。
| 函数名 | 描述 |
|---|---|
| count() | RDD中的元素个数 |
| mean() | 元素的平均值 |
| sum() | 总和 |
| max() | 最大值 |
| min() | 最小值 |
| variance() | 元素的方差 |
| sampleVariance() | 从采样中计算出方差 |
| stdev() | 标准差 |
| sampleStdev() | 采样的标准差 |
2.4 RDD的依赖关系
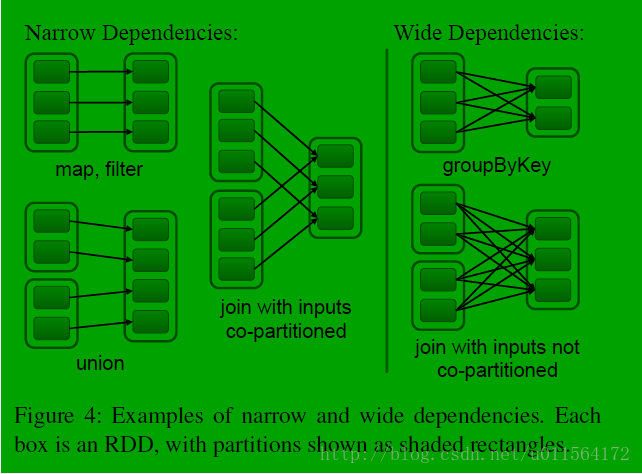
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
![image_1cmihabfmvg4lnb1fd41cme18ou9.png-62.8kB][7]
- 窄依赖
- 窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。因此,窄依赖我们形象的比喻为独生子女
- 宽依赖
- 宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle。因此,宽依赖我们形象的比喻为超生
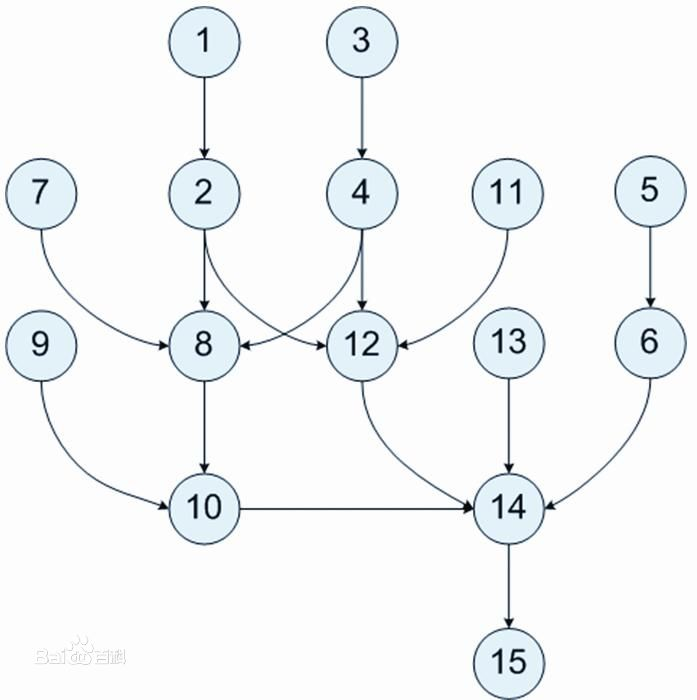
2.5 有向无环图DAG
- 概念
- ![image_1cmihm7oc64odrp1sm1qkuhldm.png-215.6kB][8]
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
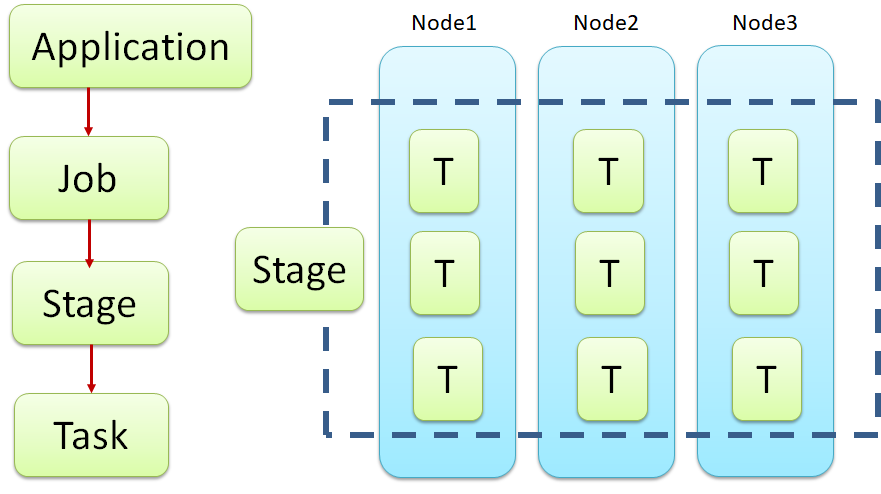
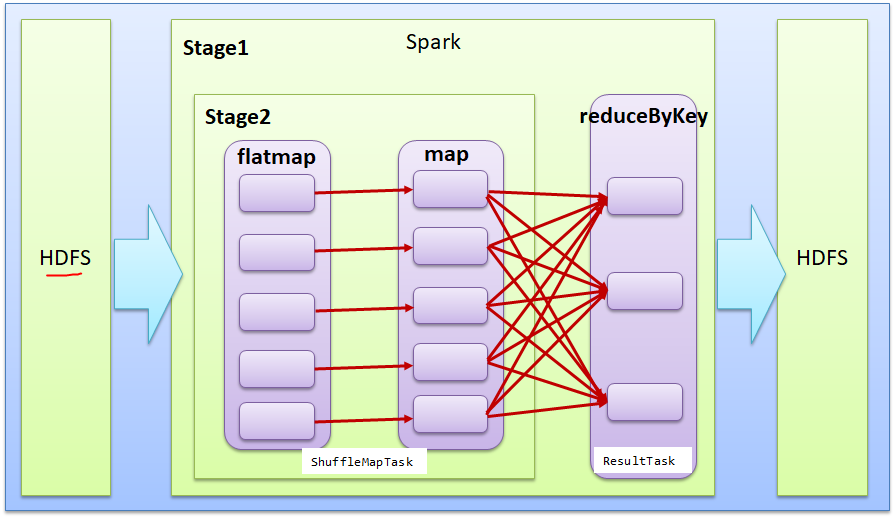
2.6 RDD 的规划
关系
:
- 一个jar包就是一个Application
- 一个行动操作就是一个Job, 对应于Hadoop中的一个MapReduce任务
- 一个Job有很多Stage组成,划分Stage是从后往前划分,遇到宽依赖则将前面的所有转换换分为一个Stage
- 一个Stage有很多Task组成,一个分区被一个Task所处理,所有分区数也叫并行度。
![image_1cmii9khqv9i1hphpfc1k52l0j1g.png-52.7kB][9]
![image_1cmii65i5aag1oki16471cim15an13.png-81.4kB][10]
2.7 血统
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
2.8 RDD的持久化
- 缓存
- persist cache
cache就是MEMORY_ONLY的persist
persist可以提供存储级别
缓存后可能会由于内存不足通过类似LRU算法删除内存的备份,所以,缓存操作不会清除血统关系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
def cache(): this.type = persist()
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)值 描述 MEMORY_ONLY 默认选项,RDD的(分区)数据直接以Java对象的形式存储于JVM的内存中,如果内存空间不足,某些分区的数据将不会被缓存,需要在使用的时候根据血统关系重新计算。 MYMORY_AND_DISK RDD的数据直接以Java对象的形式存储于JVM的内存中,如果内存空间不中,某些分区的数据会被存储至磁盘,使用的时候从磁盘读取。 MEMORY_ONLY_SER RDD的数据(Java对象)序列化之后存储于JVM的内存中(一个分区的数据为内存中的一个字节数组),相比于MEMORY_ONLY能够有效节约内存空间(特别是使用一个快速序列化工具的情况下),但读取数据时需要更多的CPU开销;如果内存空间不足,处理方式与MEMORY_ONLY相同。 MEMORY_AND_DISK_SER 相比于MEMORY_ONLY_SER,在内存空间不足的情况下,将序列化之后的数据存储于磁盘。 DISK_ONLY 仅仅使用磁盘存储RDD的数据(未经序列化)。 MEMORY_ONLY_2,MEMORY_AND_DISK_2, etc. 以MEMORY_ONLY_2为例,MEMORY_ONLY_2相比于MEMORY_ONLY存储数据的方式是相同的,不同的是会将数据备份到集群中两个不同的节点,其余情况类似。 OFF_HEAP(experimental) RDD的数据序例化之后存储至Tachyon。相比于MEMORY_ONLY_SER,OFF_HEAP能够减少垃圾回收开销、使得Spark Executor更“小”更“轻”的同时可以共享内存;而且数据存储于Tachyon中,Spark集群节点故障并不会造成数据丢失,因此这种方式在“大”内存或多并发应用的场景下是很有吸引力的。需要注意的是,Tachyon并不直接包含于Spark的体系之内,需要选择合适的版本进行部署;它的数据是以“块”为单位进行管理的,这些块可以根据一定的算法被丢弃,且不会被重建。
检查点
:
- 检查点机制是通过将RDD保存到一个非易失存储来完成RDD的保存,一般选择HDFS
- 通过sc.setCheckPointDir来指定检查点的保存路径,一个应用指定一次。
- 通过调用RDD的checkpoint方法来主动将RDD数据保存,读取时自动的从检查点目录读取
- 通过检查点机制,RDD的血统关系被切断。
- 区别
- ![image_1cmijhqbhvah35c1732coqil1t.png-36.8kB][11]
cache 和 checkpoint 是有显著区别的, 缓存把 RDD 计算出来然后放在内存中,但是RDD 的依赖链(相当于数据库中的redo 日志), 也不能丢掉, 当某个点某个 executor 宕了,上面cache 的RDD就会丢掉, 需要通过 依赖链重放计算出来, 不同的是, checkpoint 是把 RDD 保存在 HDFS中, 是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。
实操
:
2.8 RDD的分区
Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数
注意
- 只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None
- 每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。
- Hash分区
1
2
3
4
5
6
7
8def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod
rawMod + (if (rawMod < 0) mod else 0)
}
HashPartitioner分区的原理:对于给定的key,计算其hashCode,并除于分区的个数取余,如果余数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID。
- Range分区
- HashPartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据。
RangePartitioner分区优势:尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大;但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
RangePartitioner作用:将一定范围内的数映射到某一个分区内,在实现中,分界的算法尤为重要。用到了水塘抽样算法。
- 自定义分区
- 要实现自定义的分区器,你需要继承 org.apache.spark.Partitioner 类并实现下面三个方法。
numPartitions: Int:返回创建出来的分区数。
getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。
案例:假设我们需要将相同后缀的数据写入相同的文件,我们通过将相同后缀的数据分区到相同的分区并保存输出来实现。
RDD 高级
3.1 RDD的累加器
累加器用来对信息进行聚合,通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱 动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本, 更新这些副本的值也不会影响驱动器中的对应变量。 如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
Spark提供了一个默认的累加器,只能用于求和。没什么鸟用。
- 自定义累加器
- 自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。AccumulatorV2抽象类中In就是输入的数据类型, Out是累加器输出的数据类型。
最好不要在转换操作中访问累加器,最好在行动操作后访问。
转换或者行动操作中不能访问累加器的值,只能添加add,
3.2 广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个 较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发 送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。
传统方式下,Spark 会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能会在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
如果使用本地变量中,不采用广播变量的形式,那么每一个分区中会有一个Copy
如果使用了广播变量,那么每一个Executor中会有该变量的一次Copy,【一个Executor【JVM进程】中有很多分区】
主要用在百兆数据的分发
案例
:
4. Spark 的输入输出
4.1 文本文件输入输出
当我们将一个文本文件读取为 RDD 时,输入的每一行 都会成为RDD的一个元素。也可以将多个完整的文本文件一次性读取为一个pair RDD, 其中键是文件名,值是文件内容。
val input = sc.textFile(“./aaa.txt”)
如果传递目录,则将目录下的所有文件读取作为RDD。
文件路径支持通配符 * 。
通过wholeTextFiles()对于大量的小文件读取效率比较高,大文件效果没有那么高。
Spark通过saveAsTextFile() 进行文本文件的输出,该方法接收一个路径,并将 RDD 中的内容都输入到路径对应的文件中。Spark 将传入的路径作为目录对待,会在那个 目录下输出多个文件。这样,Spark 就可以从多个节点上并行输出了。
result.saveAsTextFile(outputFile)
4.2 JSON文件输入输出
其实就是文本的输入输出,需要手动导入相关jar包进行编码和解码
4.3 CSV文件输入输出
文本文件的输入和输出
4.4 SequenceFile 的输入和输出
val sdata = sc.sequenceFileInt,String
对于读取还说,需要将kv的类型指定一下。
直接调用rdd.saveAsSquenceFile(path) 来进行保存
4.5 ObjectFile的输入和输出
val objrdd:RDD[(Int,String)] = sc.objectFile(Int,String)
对于读取来说,需要设定kv的类型
直接调用rdd.saveAsObjectFile(path) 来进行保存。
4.6 Hadoop的输出和输出格式
Spark的整个生态系统与Hadoop是完全兼容的,所以对于Hadoop所支持的文件类型或者数据库类型,Spark也同样支持.另外,由于Hadoop的API有新旧两个版本,所以Spark为了能够兼容Hadoop所有的版本,也提供了两套创建操作接口.对于外部存储创建操作而言,hadoopRDD和newHadoopRDD是最为抽象的两个函数接口.
输入
:
- 针对旧的Hadoop API来说
提供了hadoopFile以及 hadoopRDD来进行hadoop的输入 - 针对新的Hadoop API来说
提供了newApiHadoopFile 以及 newApiHadoopRDD 来进行hadoop的输入
输出
:
- 针对旧的Hadoop API来说
提供了saveAsHadoopFile以及 saveAsHadoopDataSet来进行Hadoop的输出 - 针对新的Hadoop API来说
提供了saveAsNewApiHadoopFile以及saveAsNewApiHadoopDataSet来进行Hadoop的输出
4.7 文件系统的输入输出
Spark 支持读写很多种文件系统, 像本地文件系统、Amazon S3、HDFS等
4.8 数据库的输入输出
1 | class JdbcRDD[T: ClassTag]( |